
[ad_1]
Google Imagen is the new AI text-to-image generator out there. It has not been released in the public domain. But, while announcing the new AI model, the company has shared the research paper, a benchmarking tool called Drawbench to draw objective comparisons with Imagen’s competitors, and some wacky images for your subjective pleasure. It also sheds light on the potential harms of this tech.
Google Imagen: Here’s how a text-to-image-model works
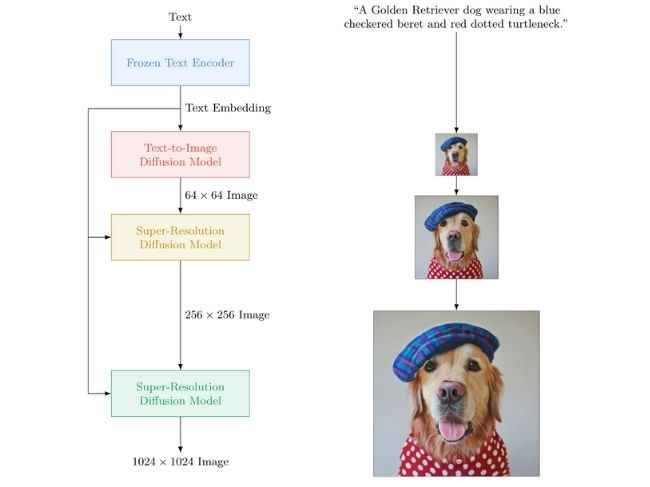
The idea is that you simply say what you want the AI image generator to conjure up and it does exactly that.
The images shown off by Google are most likely the best of the lot and since the actual AI tool is not accessible by the general public, we suggest you take the results and claims with a grain of salt.
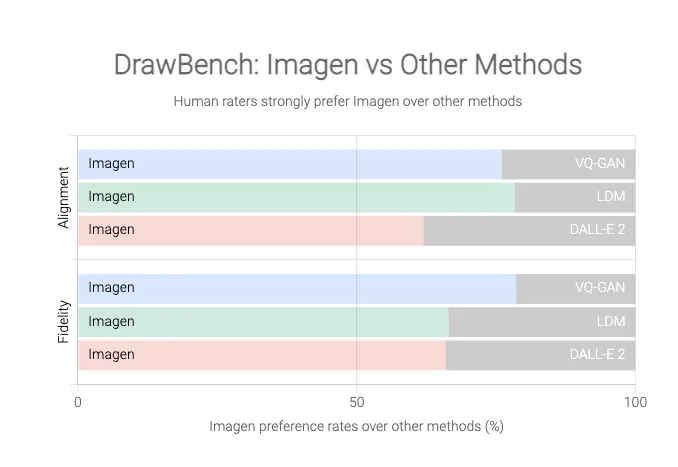
Regardless, Google is proud of Imagen’s performance and perhaps why it has released a benchmark for AI text-to-image models called DrawBench. For what it’s worth, the graphs by Google reveal how much of a lead Imagen has over the alternatives like OpenAI’s Dall-E 2.
Now, just like Open AI’s solution or for that matter, any similar applications have intrinsic flaws, that is they are liable to disconcerting results.
Just like ‘confirmation bias’ in humans, which is our tendency to see what we believe and believe what we see, AI models that filter in large amounts of data can also fall for these biases. This is time and again proven to be a problem with text-to-image generators. So will Google’s Imagen be any different?
In Google’s own words, these AI models encode “several social biases and stereotypes, including an overall bias towards generating images of people with lighter skin tones and a tendency for images portraying different professions to align with Western gender stereotypes”.
The Alphabet company could always filter out certain words or phrases and feed good datasets. But with the scale of data that these machines work on, not everything can be sifted through, or not all kinks can be ironed out. Google admits to this by telling that “[T]he large scale data requirements of text-to-image models […] have led researchers to rely heavily on large, mostly uncurated, web-scraped dataset […] Dataset audits have revealed these datasets tend to reflect social stereotypes, oppressive viewpoints, and derogatory, or otherwise harmful, associations to marginalized identity groups.”
So as Google says, Imagen “is not suitable for public use at this time”. If and when it is available, let’s try saying to it, “Hey Google Imagen there’s no heaven. It’s easy if you try. No hell below us. Above us, only sky”.
As for other news, reviews, feature stories, buying guides, and everything else tech-related, keep reading Digit.in.
[ad_2]
Source link